判断ファースト原則 — 「思考停止で運用できる」second-brain の作り方
単一入口設計は L0 を clean にしたが、入口ノート自身が append-only ログで肥大化していた。本 explainer は「全階層に bounded choice + prose-on-demand を再帰適用」する憲法と、肥大化を自動検出する linter の構築過程を、7 段で立体視する。
TL;DR
- ボトルネックは消えず、移動する。L0 を ≤40 行に固定したら、L1 が 73-476 行へ肥大した。階層ごとに同じ規律が必要。
- 3 不変条件 (bounded / prose-on-demand / recursive) を全階層に適用すれば、人間は常に少数選択肢だけに向き合える。散文は機械が保持。
- linter を health check に wired した瞬間「思考停止」が現実化。1 コマンドで 5 入口 + 20 MOC + 運用 artifact を機械検査、人間判断不要。
01入口を整えても、扉の奥はゴミ屋敷だった
Single-entry 設計 (1Plat5Ent) は L0 だけ守った。ボトルネックは L1 に移転した。

Single-entry doctrine は「階層を辿らず 1 枚から 5 方向に分岐する」設計で、L0 (入口) の認知負荷は劇的に下げた。だが各入口を開くと、入口ノート自身が「🆕 Update」「Phase N」を append し続け、73-476 行に膨れ上がっていた。ボトルネックは消えず、一段下のレイヤーに移転した。
| 階層 | 状態 | 実測 (行数) |
|---|---|---|
| L0 (00_PLATFORM) | ≤40 行で守られた clean な router | 42 |
| L1 入口 #1 (NOW) | TOP3 が 2 回、16:50 Update 累積 | 73 |
| L1 入口 #2 (DRAFTS) | session 変化ログ累積 | 104 |
| L1 入口 #3 (PROJECTS) | 🆕 Intake セクション 6 連 | 270 |
| L1 入口 #4 (KNOWLEDGE) | 🆕 Intake セクション 9 連 | 420 |
| L1 入口 #5 (HANDOFF) | ULTRATHINK Phase ログ 5 連 stack | 476 |
📚 用語解説 — Single-entry doctrine: 階層を辿らず 1 枚の入口から目的別に分岐する設計。`00_PLATFORM.md` を ≤40 行で固定し、5 方向 (NOW/DRAFTS/PROJECTS/KNOWLEDGE/HANDOFF) へ wikilink で分岐。
📚 用語解説 — Append-only log 化: 入口ノートに「今日の Update」「Phase N」を毎セッション追記し続ける状態。1 ヶ月で容易に 400 行を越え、人間が「どこを見るべきか」失う。
📚 用語解説 — Miller's 7±2: 人間が短期記憶で同時に扱える項目数。階層の可視選択肢を 5-7 に抑えると認知負荷が劇的に下がる。
🛠️ 観察方法: (1) 入口ノート各々の 非空行数を実測 (frontmatter 除く) (2) Miller's 7±2 を基準に、可視層に並ぶ「判断」または「選択肢」数を数える (3) append-only ログ marker (「🆕」「Phase N」「NN:NN Update」) を heading 単位で count (4) 60 行を超え、可視判断 ≤7 を満たさなければ赤信号。
⚠️ アンチパターン: 入口だけ整えて「設計完了」とする → 6 ヶ月後に L1 が 500 行に肥大する。每セッション「今日の状況」を append-only で追記 → ログとビューを混同。階層ごとに違う規律を適用 → 一段下に bloat が relocate するだけ。
02Decision-First Doctrine — 3 不変条件
Bounded / Prose-on-demand / Recursive — 全階層に再帰適用する憲法。
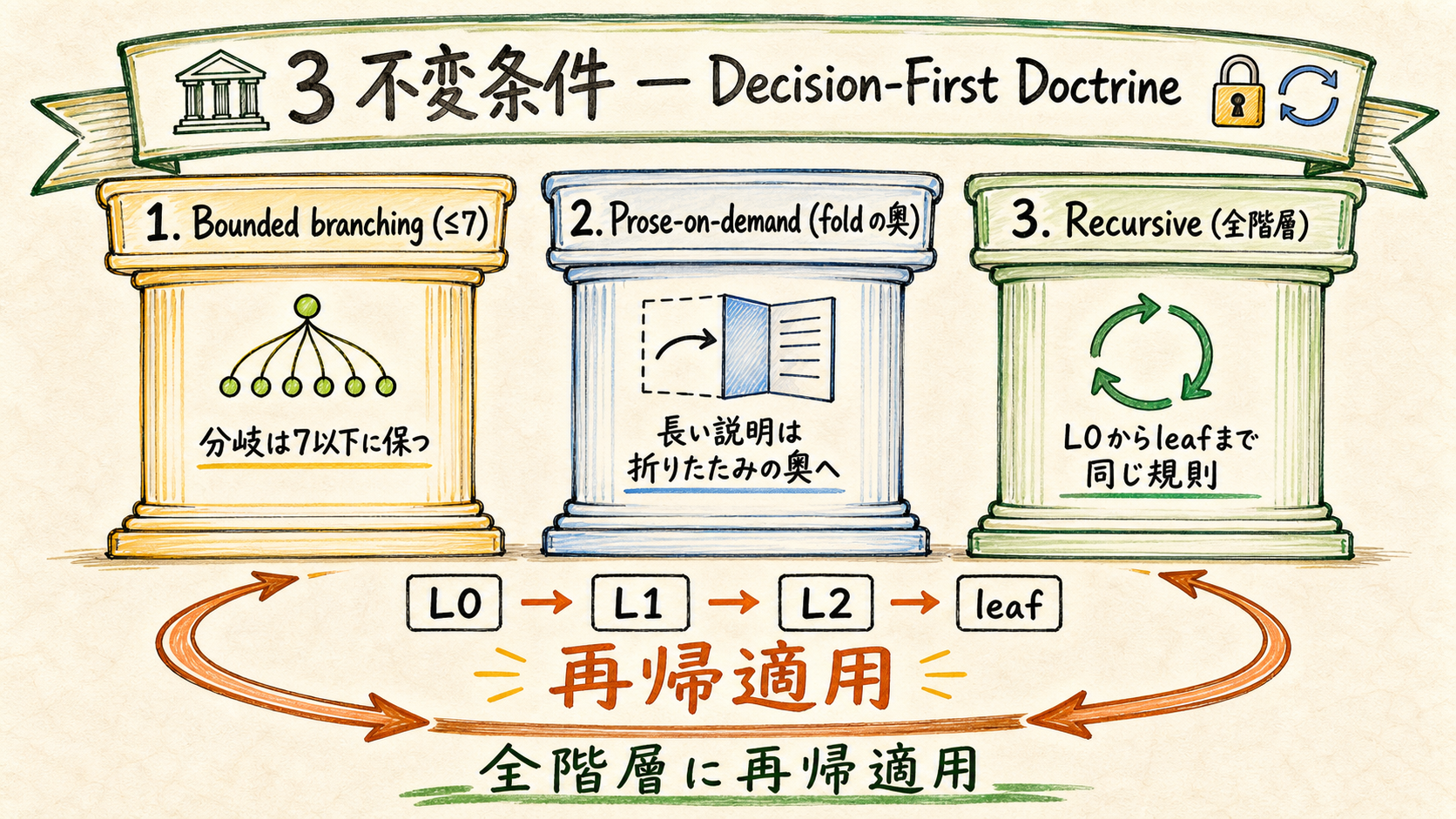
人間は常に 少数の選択肢だけに向き合う。散文 (本文・根拠・履歴) は機械が保持し、人間が要求した時だけ leaf の fold から出す。この一文を 3 不変条件に分解し、L0 から leaf まで再帰適用するのが本ドクトリンの全て。
| 不変条件 | 何を制約するか | 違反すると |
|---|---|---|
| Bounded branching | 可視選択肢を ≤7 (理想 5) に絞る | Miller's limit 超で迷子、選び抜きの摩擦 |
| Prose-on-demand | 散文は leaf の折り畳み callout の中だけ | default-visible に段落が並び、読まないと判断不能 |
| Recursive | L0 から leaf まで全階層が上 2 つを満たす | 一段でも破れたら、そこが新しいボトルネック |
📚 用語解説 — Bounded branching: 各層で可視な「次の一手」の枝を 7 以下に保つ規律。階層が深くなっても、人間は常に 7 個の選択肢の中から選ぶだけ。
📚 用語解説 — Prose-on-demand: 「散文 (paragraphs of explanation) は、誰かが要求した時だけ展開する」原則。default-visible 層には散文を置かず、判断・選択肢・table・list のみ並べる。
📚 用語解説 — Recursive 適用: 同じ規律を L0 (入口) → L1 (入口ノート) → L2 (hub/MOC) → L3 (card) → L4 (leaf=choice) まで一貫適用。階層ごとに UI が違うと、人間の認知モデルが分裂する。
🛠️ 運用方法: (1) 新規ノート作成時、まず 選択肢から書く (card stack 形式) (2) 散文は [!info]- や [!mail]- など 折り畳み callout の中に閉じ込める (3) 既存ノート編集時、可視層の散文を fold へ移動 (4) 新規階層を作る時、必ず親階層と同じ 3 不変条件をテンプレ化する。
⚠️ アンチパターン: 「概念だけ」で実装しない (linter なしで規律は崩壊)。階層ごとに違う UI を作る (再帰性破壊)。「fold したから OK」と長いノートをそのまま残す (bounded は サイズの制約、fold は 可視性の制約、両方必要)。
03Card Stack — L2 hub の判断ファースト形式
1 判断 = 1 card。可視層は見出し + 選択肢チップの 2 行のみ。
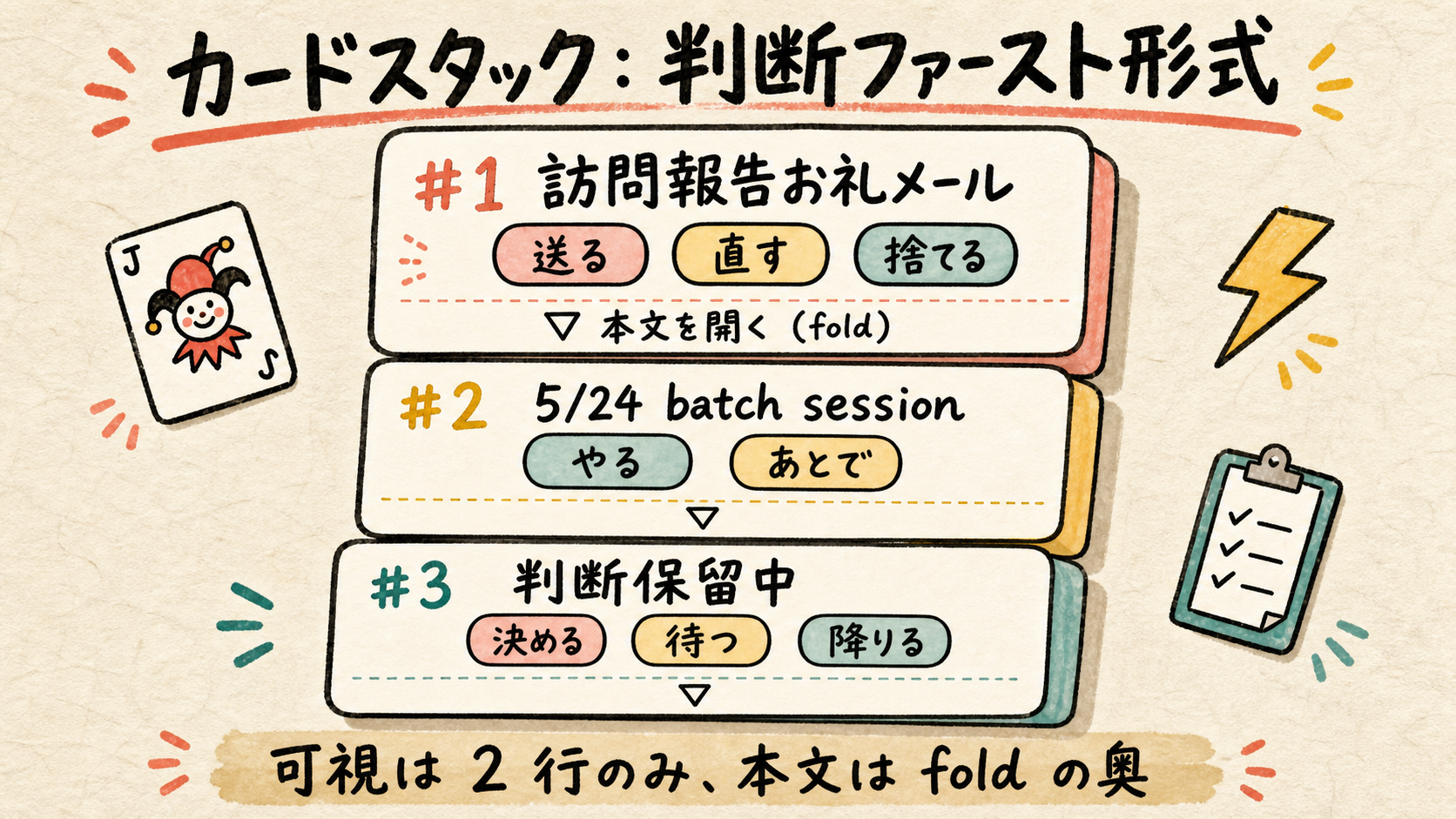
L2 hub は「読む文書」でなく「判断キュー」。各 card は callout で常時表示、見出し 1 行 + 選択肢チップ 1 行の 計 2 行のみ可視。本文・根拠・履歴は nested 折り畳み callout に閉じ込め、要求された時だけ展開する。
| 型 | 選択肢チップ (固定 2-4 個) |
|---|---|
| メール | 送る / 直す / 捨てる |
| タスク | やる / あとで / 捨てる |
| 判断 | 決める / 待つ / 降りる |
| 待ち (外部依存) | 催促 / 待つ / 降りる |
📚 用語解説 — Card: 1 判断を表す callout block。常時展開 (折り畳まない)、見出し + 選択肢チップの 2 行が可視層、それ以外は nested 折り畳み。
📚 用語解説 — Choice chip: inline code (バッククォート) でレンダリングされる選択肢ラベル。型ごとに 2-4 個固定、乱立禁止。
📚 用語解説 — Leaf vocabulary: 最終単位 (leaf) の選択肢セット。型ごとに語彙を固定することで、ユーザーが「次の手」を考えずに済む。
🛠️ 運用方法: (1) hub を # 今日の判断 — N 件 見出しで開始 (2) 各 card を緊急度順に通し番号 (3) 可視カード ≤7、超過分は「その他 M 件」fold に畳む (4) 新しい型を足す時は語彙を 2-4 個に固定、本表に追記。
⚠️ アンチパターン: 型ごとに語彙を乱立 (3 種以上は迷う、固定 2-4 個)。fold 内にさらに判断を隠す (leaf は fold の外、選択肢は常時可視)。「全項目を 1 画面で見せたい」と可視カードを 10+ に増やす (Miller's limit 違反、グループ化必要)。
04Linter Enforcement — 機械が肥大化を見張る
validate_decision_first.py + health check 統合 = 「思考停止」の本体。
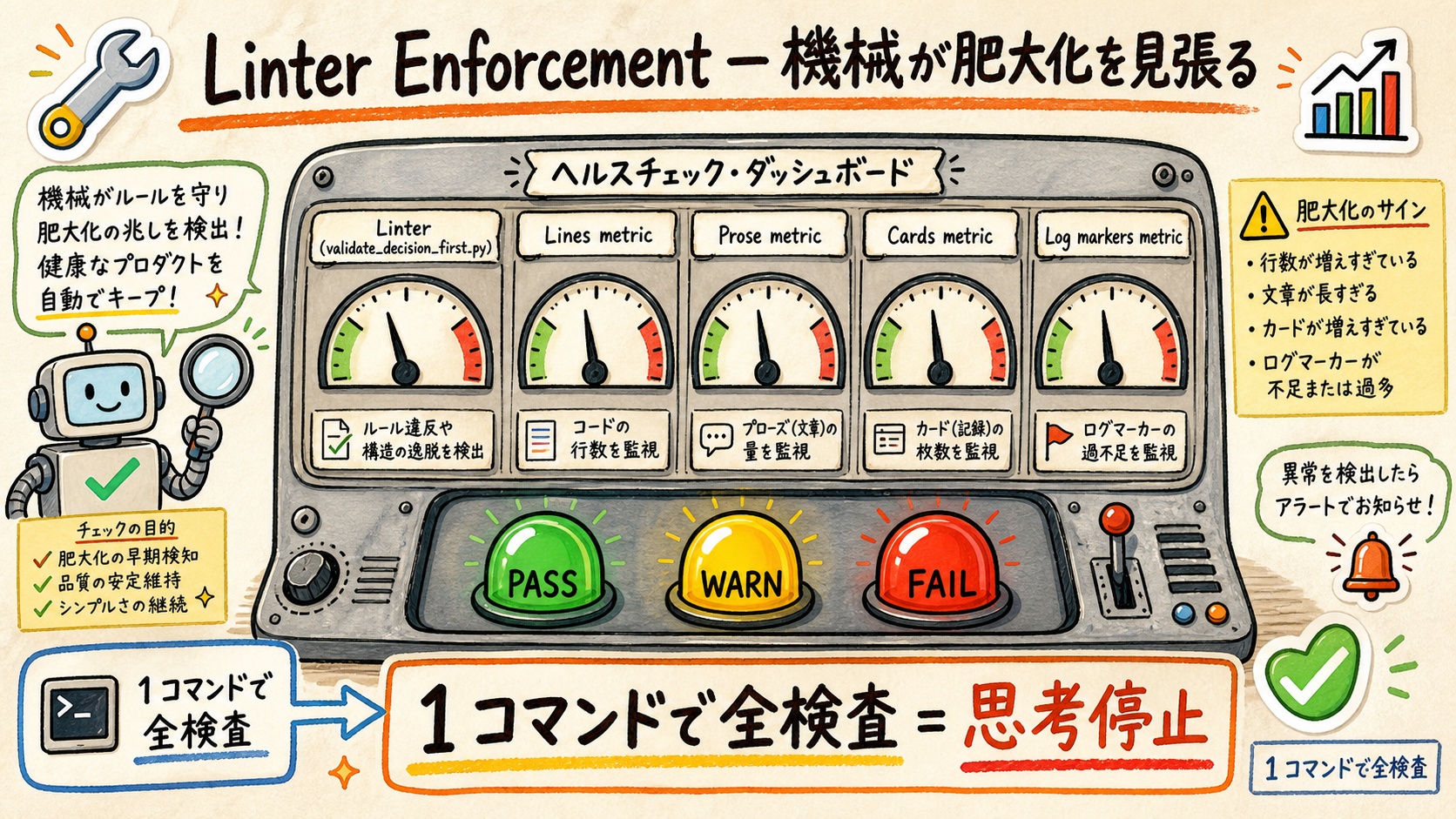
ドクトリンを書いただけでは「気をつける」止まり。機械が肥大化を見張る段階で初めて「思考停止」が現実化する。linter は 4 metric (lines / 可視 prose / cards / log markers) で各ファイルを PASS/WARN/FAIL 判定し、既存 health check スクリプトに統合される。
| Metric | PASS 条件 | FAIL 検出例 |
|---|---|---|
| Content lines | ≤70 (入口ノート) / ≤150 (ハブ) | 1 ヶ月放置で 200+ 行に肥大 |
| 可視 prose lines | ≤5 (default-visible 層の散文) | callout 外に段落 10+ 行 |
| Card count | ≤7 (Miller's limit) | 判断 14 個並列、グループ化必要 |
| Log markers | ≤2 (heading 内の append marker) | 「🆕」「Phase N」が 6 連 heading |
📚 用語解説 — Linter: 自動検査ツール。本ドクトリンでは validate_decision_first.py が 5 入口 + ハブ + sub-hierarchy を 4 metric で機械評価。
📚 用語解説 — Health check integration: 既存の鮮度 check スクリプト (PowerShell) に linter を wire。pwsh -File Test-PlatformHealth.ps1 一発で鮮度 + 構造肥大の両方判定、人間判断不要。
📚 用語解説 — PASS / WARN / FAIL: 3 段階判定。WARN は許容 (例: MOC navigation 密度)、FAIL は再構築必須 (例: 入口ノート >150 行)。
🛠️ 運用方法: (1) linter を新規追加した時、必ず既存 health check に 統合する (新しいコマンドを増やさない) (2) 1 コマンド = 全 metric 検査の状態を維持 (3) FAIL が出たら即対象ファイルを decision-first 再構築 (4) WARN は許容、ただし境界値に注意。
⚠️ アンチパターン: 機械検査を skip して人手 audit に頼る (続かない、月次が必ず破綻)。linter を別コマンドにして既存 check と分離 (1 コマンドの統合が「思考停止」の本体)。閾値を都度調整して FAIL を消す (根本原因 = 肥大化を直すべき)。
05Sub-hierarchy + Circulation — leaf まで再帰する閉ループ
↑L1 / ↔sibling / 🏠L0 backlink で「どこから入っても、どこへでも戻れる」。

L1 入口が「判断キュー」なら、L2 (hub / MOC / Facility Index 等) は「縦の入口」。同じ 3 不変条件に 循環が追加要件。各 L2 ファイルは「↑ 親階層 / ↔ sibling / 🏠 root」の 3 方向に backlink を持ち、どこから入ってもどこへでも戻れる閉ループを形成する。
| 階層 | 可視に出すもの | fold の奥 |
|---|---|---|
| L0 (root) | 5 入口 | (なし) |
| L1 (入口ノート) | 判断キュー (≤7 cards) | 本文 / 履歴 / 詳細 |
| L2 (hub / MOC) | navigation table or 判断キュー | literature / open questions / related |
| L3 (1 card) | 見出し + 選択肢チップ (2 行) | 本文 / 根拠 |
| L4 = leaf | 選択肢そのもの | (これより深くしない) |
| L5 (fold の奥) | — | 本文 / 根拠 / 履歴 (要求時) |
📚 用語解説 — 循環 (Closed loop): 各 L2 ファイルが ↑ 親階層 / ↔ sibling / 🏠 root の 3 方向 backlink を持つ規律。「どこから入ってもどこへでも戻れる」状態。
📚 用語解説 — Sibling navigation: 同レベルの隣接ファイル (前/次 facility、関連 MOC) への横移動リンク。深さ方向だけでなく幅方向の navigation を確保。
📚 用語解説 — Incremental rollout: 全ファイルを一気に変更せず、sample 1-2 件で paradigm 確立 → wave 単位で漸進適用。Big Bang を禁止する規律。
🛠️ 運用方法: (1) L2 共通骨格 (frontmatter + 見出し + ナビゲーション + 詳細 fold + 循環 footer) をテンプレ化 (2) sample 1-2 件で paradigm 確立 → 後続を wave 単位で展開 (3) 各 wave 後に linter (--path) で対象を PASS 確認 (4) 循環 footer は最後の必須 section、欠落 = FAIL 扱い。
⚠️ アンチパターン: 一気に 40+ ファイルを変更 (Big Bang、品質保てない、修正 loop 不能)。循環 backlink を「nice-to-have」扱い (1 方向 navigation だと深い階層から戻れず迷子)。L2 で散文を可視層に許容 (規律が一段下で崩れる)。
06Skill Regeneration — append 禁止、log は git へ退避
適用継続のための skill discipline。ドキュメントを書き直すと既存 skill が古い形に戻す問題。

decision-first 形式でファイルを 1 度書き直しても、生成 skill (daily 処理 / handoff 生成 / refresh 等) が append-style なら次回また肥大化する。skill 本体を regenerate-style + _log 退避に更新する必要がある。古い content は別 _log ファイルや git 履歴で復元可能にする。
| 項目 | Append-style (✗) | Regenerate-style (✓) |
|---|---|---|
| セッション処理 | 末尾に「今日の Update」追記 | 全文上書き、新規 decision-first 形式 |
| 過去 content | ファイル内に永続蓄積 | git 履歴 or _log ファイルへ退避 |
| 復元方法 | ファイル内を scroll | git show HEAD~:path |
| 肥大化 | 1 ヶ月で 500+ 行 | 常に <60 行 |
📚 用語解説 — Regenerate-style: ファイルを毎回新規生成し、過去 content は別レイヤー (git / log file) に退避する pattern。append-only ログから「人間用の bounded view」を分離する。
📚 用語解説 — `_log` 退避: 古い content を同名ファイルから別 _log サフィックスファイルに移動するか、git 履歴に commit して削除。bounded view と log を物理分離。
📚 用語解説 — Skill quality gate: skill の SKILL.md に「G6: 生成物が decision-first 形式で PASS」を追加し、生成完了の判定条件に組み込む。
🛠️ 運用方法: (1) 既存 skill の SKILL.md に quality gate (G6) を追加し、生成物が linter で PASS することを完了条件にする (2) skill workflow から「append」を禁じ「regenerate」を default にする (3) handoff template を decision-first 形式に書き直す (4) refresh 系 skill の Step 内に linter 実行を組み込む。
⚠️ アンチパターン: ドキュメントを書き直すだけで skill 本体を放置 (次回生成で元の形に戻る)。古い content をファイル内に「念のため残す」(肥大化、bounded 違反)。skill quality gate を skip (規律は数日で崩れる)。
07Ritual Mechanism — append-only ログ × bounded view (深層モデル)
第二の脳の最も深い model。月次儀式 (清算 / 月締め / 健康診断) も同じ pattern。

第二の脳の最も深い model: 「整理された棚」ではなく、append-only な蓄積層の上に bounded な判断ビューを render するもの。蓄積層 (機械用) は無限に増えてよい。判断ビュー (人間用) は常に bounded・decision-first。月次儀式 (経費清算 / 月締め / 健康診断) も同じ pattern で抽象化できる。
| 儀式 | Append-only substrate | Bounded render (人間用) |
|---|---|---|
| 日次処理 | 全 mail / 送信履歴 index / draft 全件 | 今日の判断 ≤7 cards |
| 月次経費清算 | credit card 明細 + 出張記録 (全件) | 突合ワークシート (1 月分の差分のみ) |
| 月次月締め | ファイル全件 (drafts / projects / ZK) | manifest (今月 archive 候補のみ) |
| 月次健康診断 | rules / skills / memory 全件 | audit 結果 (≤7 件の改善提案) |
📚 用語解説 — Append-only substrate: 機械が読む層。session ログ / draft 全件 / file index など、無限に蓄積してよい。人間は直接読まない。
📚 用語解説 — Bounded render: 人間が読む層。入口ノート / ハブ / カード、常に bounded・decision-first。蓄積層から都度 render される。
📚 用語解説 — Dry-run + apply gate: 月次儀式 skill が必ず実装する 2 段 gate。1 段目 = dry-run で manifest を提示、2 段目 = --apply --confirm <key> で破壊的操作を実行。誤実行を防ぐ。
🛠️ 運用方法: (1) 月次儀式 skill を作る時は 5 module architecture (Ground Truth → Plan → Build → Verify → Apply gate) (2) Apply gate は必ず dry-run default + --apply --confirm <key> 二段 (3) 既存 skill 設計をこの抽象化で見直す (4) append-only ログを人間に直接読ませない、bounded render 経由のみ。
⚠️ アンチパターン: ログを人間に直接読ませる (append-only と bounded view の境界が崩れる)。destructive ops を gate 無しで実行 (誤実行 = 復元コスト高)。儀式 skill ごとに異なる architecture (5 module を統一テンプレ化しないと、各 skill が独自進化して負債になる)。
結論
- ボトルネックは消えず、移動する。階層ごとに同じ規律 (bounded / prose-on-demand / recursive) を適用しないと、L0 を整えても L1 が肥大する。
- 「思考停止」は linter で初めて現実化する。ドクトリンを書いただけ・skill rule に書いただけでは、規律は数日で崩れる。1 コマンドの health check に統合した瞬間、人間判断は不要になる。
- 第二の脳の最も深い model = append-only 蓄積 × bounded render。日次処理も月次儀式も同じ pattern。蓄積層は無限に増えてよい、人間が向き合うビューだけ常に bounded であればよい。